Pipelining of selectors for better results.
Prerequisites.
To get the most out of this article, it's better to read Getting started page beforehand.
How pdf2Data extracts values.
To extract anything from PDFs, you should create a data field and add at least one selector (i.e. predefined parsing rules) to that field.
The order of the selectors is important. Selectors of a data field form a parsing pipeline, where each selector receives data from the previous selector in the pipeline, converts it to the necessary format, filters the data out, and sends the filtered data to the next selector. The data extracted by a data field is the result of the last selector in the pipeline.
When pipelining makes sense.
Depending on the use-case and the content of pdf PDFs you want to parse, you can approach the data extraction in different ways. In the vast majority of cases, using only one selector is enough to get extract the needed value.
However, sometimes it's worthwhile to use a pipeline of multiple pipelining selectors to refine the output.
The following couple of examples show when pipelining makes sense.
Using picker to remove duplicates, or useless data from the output.
Let's assume, we need to detect whether the document you're processing is an invoice or a purchase order.


The fields you need from these two documents are similar to each other. But you need to use the extracted data differently, so it's helpful to know what type of document it is.
The type can be detected from the text from in the first text block in both PDFs. However, we cannot assume the position of that text is static, so you cannot use Boundary .
Instead, you can use a combination of the following selectors:
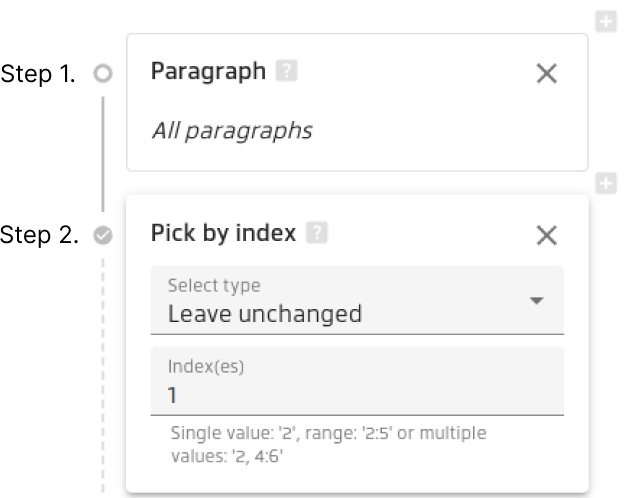
As you can see, there are two steps in this pipeline.
We will use the invoice to show the output for this example. Feel free to request trial access and test this approach with your documents on pdf2Data.online.
Step 1.
Paragraph detects all text blocks in the PDF:

Step 2.
Use Pick by index to return the first found result:
You can pick elements with the "Pick by index" selector, by using:
- A number to specify the index of the element in the output of the previous selector;
- A negative number to count from the end of the list;
- You can also use ranges. Ranges can mix both direct and reverse notation, e.g.
1:2, 7:-1will extract the 1st, 2nd element, and then all elements from the 7th to the last one (-1).
You need to extract a value from a specific page/region.
In this case you can use the Search area.
The following example shows quite an interesting and complex use-case – the extraction from a PDF with a multi-column layout.
The fragment of the form below has 3 columns, and we need to extract all checked options.

For this case, you can use here the following steps with selectors and search area:
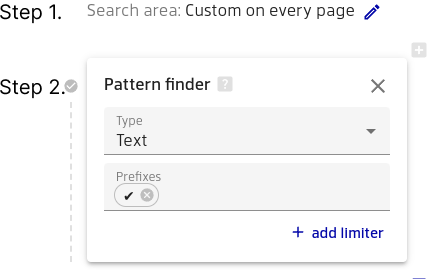
This pipeline consists of 2 steps.
Step 1.
The Search area allows you to extract the entire content in selected region as a collection of lines:
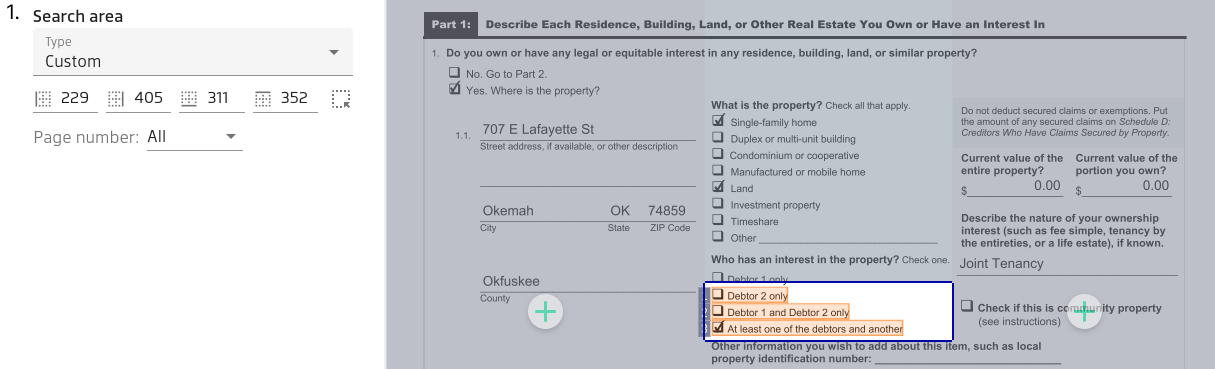
Let's click on top button to include top area for result:
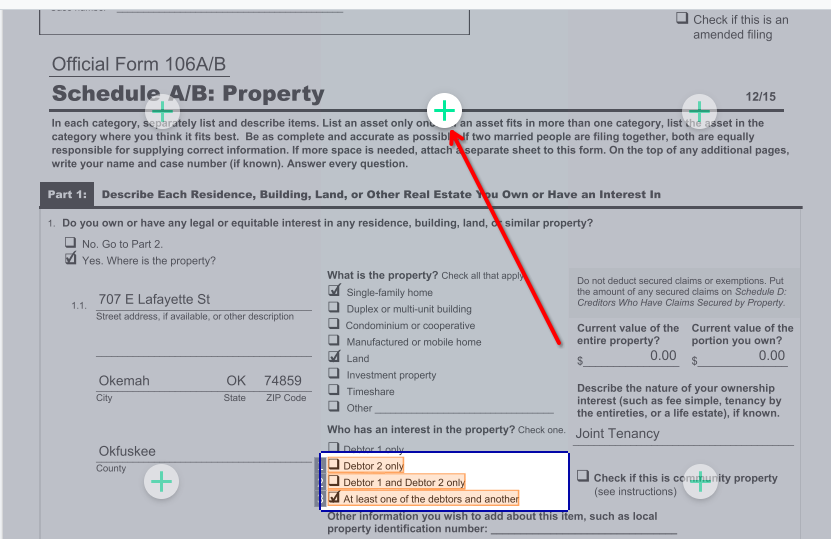
The result will be:

Step 2.
However, we want to filter out all the "unchecked" lines, so we add the Pattern finder to the pipeline:

You can copy the checkbox symbol right from your document
The output of the pipeline contains 3 extracted values:

And there you have it, two handy examples showing you can use pdf2Data's powerful pipelining feature to refine the PDF extraction output.
Preview results of intermediate pipeline steps
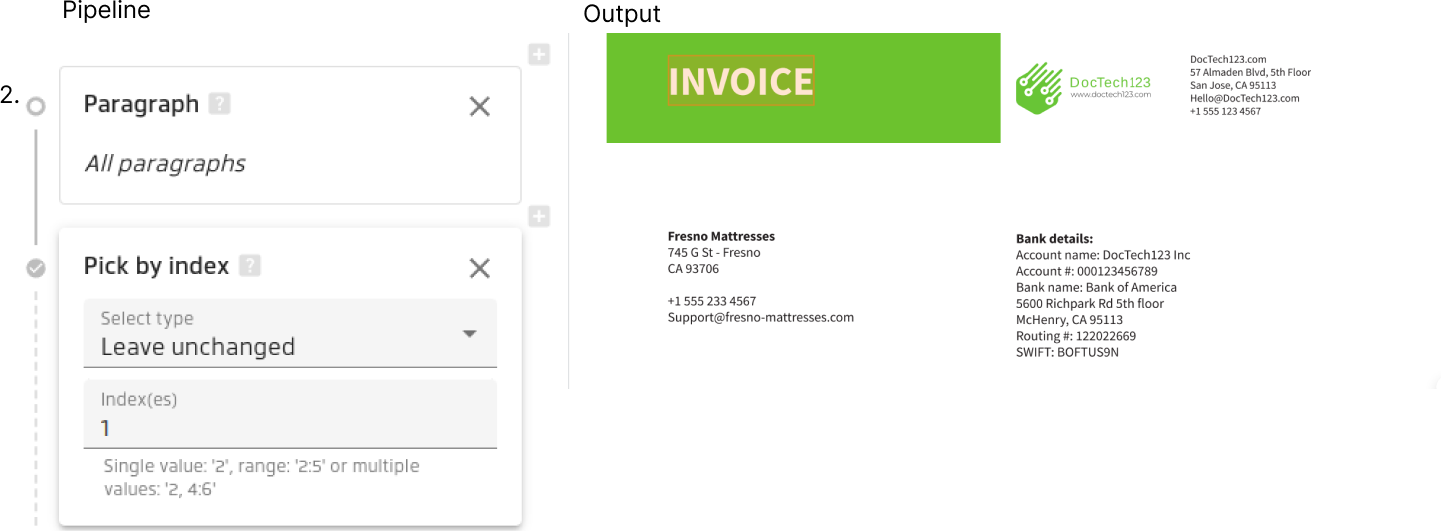
Since 4.5.1 you can preview the result of the pipeline up to specific step. Let's consider an example.
The data field contains custom search area, two selectors and one result.

The output of the pipeline contains 1 extracted value:

Let's consider you want to check what the results were on step "Pick by index" selector. For that you should click on that selector and after that you will see the results for the part of the pipeline excluding steps which follows selected selector. When you preview the results only for the part of the pipeline you will see the tip with helping text, that says as that we are in preview mode.

In our example during the preview the result contains 2 extracted values:

To exit from preview mode you can press the "Escape" button or click on close button on banner.
If Search area is active the preview mode is reset, and you should see the entire pipeline result again.